-
ChatGPT를 이용해서 추천시스템 만들기Recommendation System 2023. 10. 4. 19:28
목차
1. 환경세팅
1-1. OpenAI에서 API KEY 받기
OpenAI 사이트 로그인 -> 프로필에 view API Keys

-> Create new secret key를 해서 임의로 이름을 만들고 KEY를 받는다. 이 KEY는 메모장에 따로 메모해두기. 기존에 있는 KEY는 볼 수 없으므로 주의하기

1-2. 테스트 해보기
google colab에서 실습했음.
! pip install openai ! pip install python-dotenv ! pip install -U sentence-transformers import os import openai from dotenv import load_dotenv import pandas as pd import torch from sentence_transformers import SentenceTransformer, util from tqdm import tqdm from ast import literal_evalopenai.api_key = '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' response = openai.Completion.create( model = 'text-davinci-003', prompt = '안녕. 내 이름은 강지호야. \nQ: 내 이름이 뭘까? \nA:', temperature = 0, max_tokens = 100, top_p = 1, frequency_penalty = 0.0, presence_penalty = 0.0, stop = ["\n"] ) print(response.choices[0].text.strip())
잘 동작하는 것을 알 수 있음 !
2. 추천시스템 구조
- Data : kaggle의 The Movies Dataset 링크
1. 텍스트 형태의 메타 정보를 임베딩 -> D
2. 원하는 영화를 물어보는 Query를 임베딩 -> Q
3. D와 Q 사이의 cosine similarity 계산하여 topK 뽑아주기,
2-1. Preprocessing
- needs_cols : 전체 데이터 중, 유의미한 의미를 갖는 text column
- num_cols : 빠른 학습과 openAI의 credit을 아끼기 위해 데이터 축소할 예정. 이 작업을 위한 column
data = pd.read_csv('/content/drive/MyDrive/Recsys/movies_metadata.csv', sep=',') need_cols = ['id', 'title', 'genres', 'original_language', 'overview', 'release_date'] num_cols = ['popularity', 'vote_average', 'vote_count'] data = data[need_cols+num_cols] data.dropna(inplace=True)
- 빠른 학습과 리소스 절약을 위해 어느정도 유명한 아이템만을 사용할 예정. num_cols를 기준으로 중위값 이하는 drop
원본 [45466] -> dropna [44425] -> 중위값 이하 삭제 [5831]
df = data.copy() num_cols = ['popularity', 'vote_average', 'vote_count'] print('before len:', len(df)) for col in num_cols: df[col] =df[col].astype(float) col_mean = df[col].quantile(0.5) df = df[df[col] >= col_mean] print('after len:', len(df), '\n') df.reset_index(inplace=True, drop=True) df[num_cols].describe()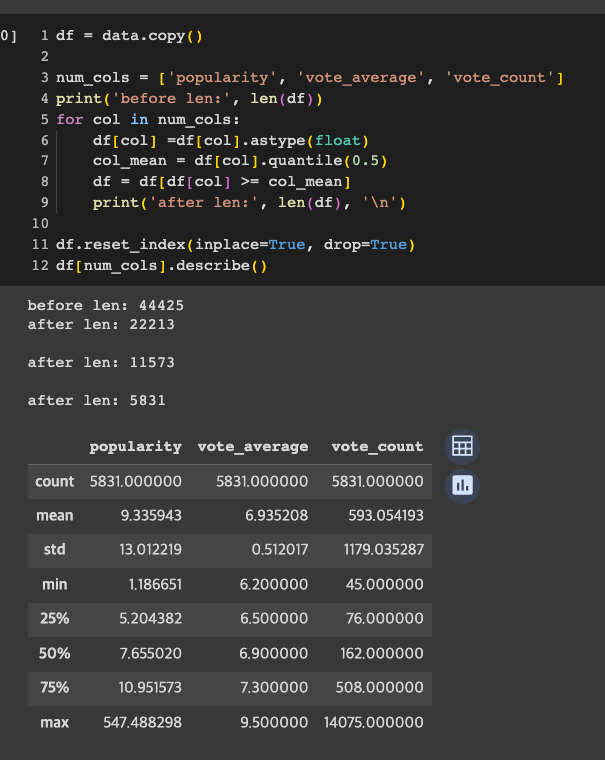
- 장르 카테고리 text만을 뽑기 위한 EDA를 진행.
- feature : 사용하고자 하는 text column을 concat

2-2. Embedding Vector 만들기 (OpenAI)
- 이전 포스팅에서도 말했지만, ChatGPT는 GPT-3.5-turbo 모델이고, GPT3.5 이전의 좀 더 가볍고 싼 버전들도 사용할 수 있다. 다만, 오늘 실습의 목적은 ChatGPT를 활용한 의도 파악이 아닌, text embedding을 활용한 의미 추출이기 때문에, 우리는 (정확히 말하면) ChatGPT를 사용하는 것이 아닌, OpenAI가 제공하는 Embedding 모델을 사용할 것이다.
- OpenAI가 Embedding 모델 중 text-embedding-ada-002를 제일 빠르고, 싸고, 사용하기 간단하다고 추천해주었다.

- df['feature']에 apply method를 이용할 수도 있지만, 진행 상황이 눈에 안보여서 tqdm으로 만들어줌.
- 5831개의 text를 embedding하는데 약 15분이 걸렸다.
- feature의 max_token은
- OpenAI의 embedding차원은 1536이다.
openai_model = 'text-embedding-ada-002' overview_emb = [] for i in tqdm(range(df.shape[0])): text = df['feature'][i] result = openai.Embedding.create(model = openai_model, input = text) result_emb = result['data'][0]['embedding'] overview_emb.append(result_emb) df['openai_emb']= overview_emb print(df.columns) print(df.shape) df.head(2)
- 추천 받고 싶은 내용을 query로 주고, 상위 10개만 뽑아봤다.
top_k = 10 query = 'similar to Andy, Woody, Buzz movie' query_encode = openai.Embedding.create(model = openai_model, input=query) query_encode = query_encode['data'][0]['embedding'] cos_scores = util.pytorch_cos_sim(query_encode, df['openai_emb'])[0] top_results = torch.topk(cos_scores, k=top_k) print(top_results)
- query는 (토이스토리에 나오는 인물인) Andy, Woody, Buzz 영화와 비슷한 것을 추천해달라고 한다. 뽑힌 결과를 봤을 때, 영화 <토이스토리> 시리즈가 전부 상위권에 링크되어 있다. overview에 해당 인물들이 text로 들어가 있기 때문이다.
top_result_id = top_results.indices.tolist() top_result_score = top_results.values.tolist() result_df = df[df.index.isin(top_result_id)] result_df.index = top_result_id result_df['score'] = top_result_score result_df[['score', 'title', 'genres', 'overview', 'release_date', 'popularity']]
2-3. Embedding Vector 만들기 (huggingface)
- 이번에는 huggingface의 sentence embedding 모델로 똑같이 구현해보았다. huggingface의 sentence-transformers 중 가장 다운로드 수가 많은 all-mpnet-base-v2 모델을 사용했다. 해당 모델은 768차원의 array를 반환한다.
- 학습 시간은 33분이 걸린다. OpenAI보다 두배 더 느리다. 물론 모델에 따라 다를듯.
hugging_model = SentenceTransformer('all-mpnet-base-v2') hugf_emb = [] for i in tqdm(range(len(df))): text = df['feature'][0] emb = hugging_model.encode(text) hugf_emb.append(emb) df['hugf_emb'] = hugf_emb df.head(2)
결과값을 보면 1위는 토이스토리이지만, 관련 없어 보이는 영화가 많다.
확인해보니 모든 영화에 대해 score가 모두 똑같이 나옴,, 무언가,, 잘 안된 것,,,
embedding 모델과 Query를 바꿔서 여러번 시도했을 때, score 자체는 다른값이 나왔지만 역시나 모든 영화에 대해 같은 값이 나옴.
대체 왜그런건지 좀 더 살펴봐야겠음...
top_k = 10 query = 'similar to Andy, Woody, Buzz movie' query_encode = hugging_model.encode(query) cos_scores = util.pytorch_cos_sim(query_encode, df['hugf_emb'])[0] top_results = torch.topk(cos_scores, k=top_k) print(top_results) hugf_top_result_id = top_results.indices.tolist() hugf_top_result_score = top_results.values.tolist() hugf_result_df = df[df.index.isin(hugf_top_result_id)] hugf_result_df.index = hugf_top_result_id hugf_result_df['score'] = hugf_top_result_score hugf_result_df[['score', 'title', 'genres', 'overview', 'release_date', 'popularity']]
3. Future work
- 영화 말고 다른 산업군 데이터 or 한국어 데이터 or 한국어 모델로 변경해보기
- 결과 더 디테일하게 분석해보기
- 평가지표 설정하여 베이스라인과 비교해보기
'Recommendation System' 카테고리의 다른 글